Addressing scalability and performance in complex enterprise platforms
Context setting
“Computer science is fundamentally about what we do with data. This can be either processing data, moving data from one place to another or storing the data”. Therefore increasing the capacity , performance of a platform can be answered through 5 principles;
How can we improve the processing speed of a data unit?
How can we improve the transmission speed of a data unit?
How can we reduce (optimise) the amount of data moved?
How can we reduce (optimise) the amount of processing?
How can we reduce the number of data hops?
When there is a scalability, performance and reliability problem I look at above dimensions to assess how well the system is architected, how well the engineering is done and how efficient the business processes are? Always its not just a technology problem but also a mix of technology and business/process problems and deficiencies that results in bringing a system down to its knees!.
Once I was handed over a significantly large platform that served 80+ global markets (hence 24*7, 6+ days up time) , that has more than 1000 processes , 1000+ integration points, 1000+ users, source code beyond 10m LoC, 8 digit Euro annual running cost and a failure will result in systemic risk in a critical area of financial services industry.
The structured approach we adopted and executed resulted in improving the capacity by 10X, resilience by 40X and halved the running costs in 2 yrs
Previous teams had struggled to figure out what to do;
Where do we start?
Can infrastructure solve it?
Do we have to re-write the whole platform?
In this situation unless there is a structured technical approach, the whole endeavor can fail…
In below write up I try to dissect and elaborate what I have done without exposing the actual application details itself and some of the complex solutions. Any one interested do DM me.
Approach?
In order to achieve sustained benefits delivered through a continuous improvement program the approach adopted should be able to
Identify the biggest bottlenecks
Formulate the solutions and efforts for remediation
Rank the solutions based on the impact in capacity limitations, coverage of the impact (i.e. more components the better), effort /cost and risk.
Ensure the front to back capacity is balanced when they are deployed instead of providing a skewed /unbalanced capacity across different components.
Continue the iterative process with the next level of remediation items, until the overall capacity targets are met. This requires executing subsequent iterations based on the results and observations from previous step and feeding them again to the start of the cycle.
Below figure shows the structured approach I set up to analyse the significantly large problem.
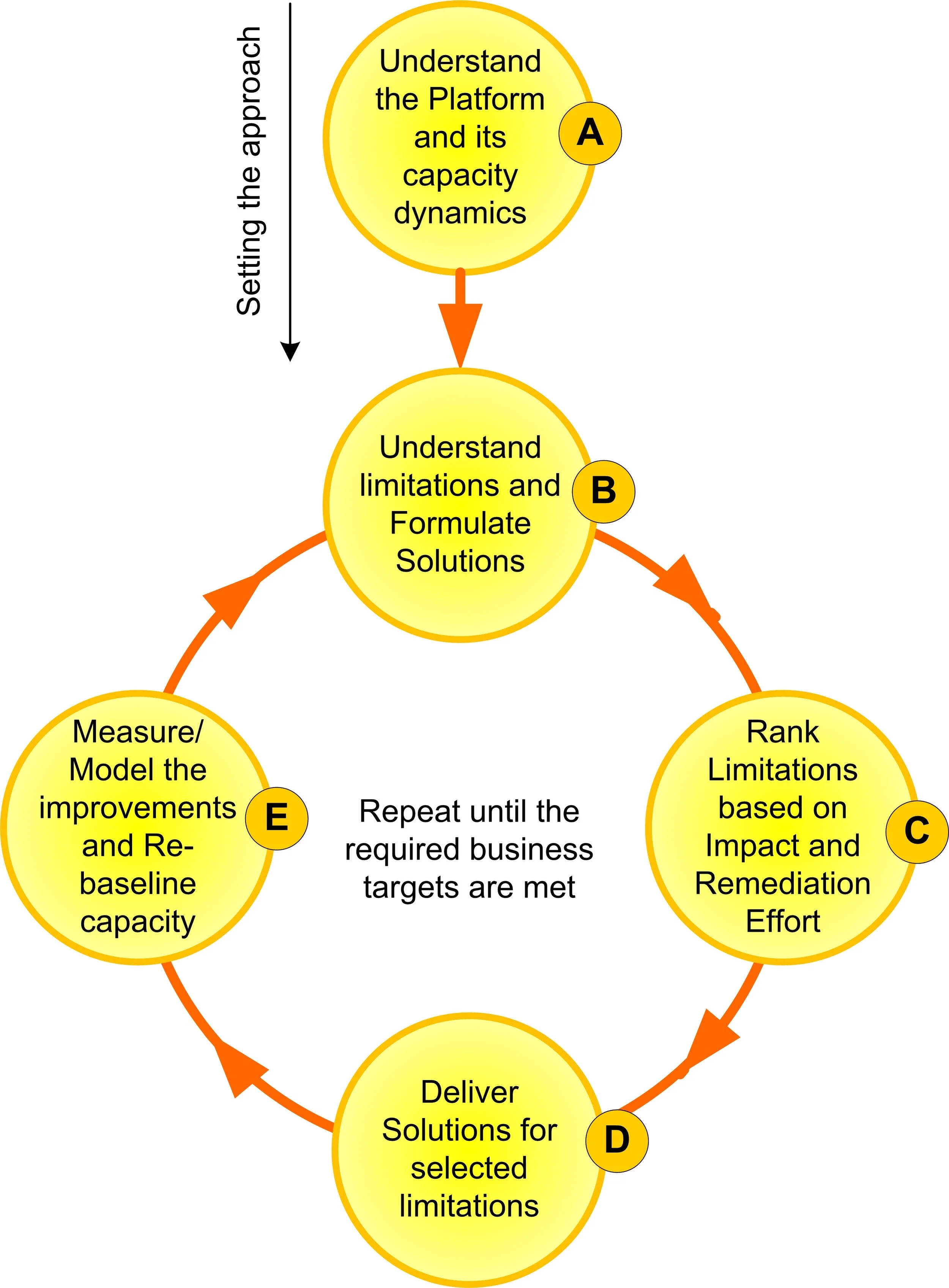
Lets discuss each step….
Step A: Understand the Platform
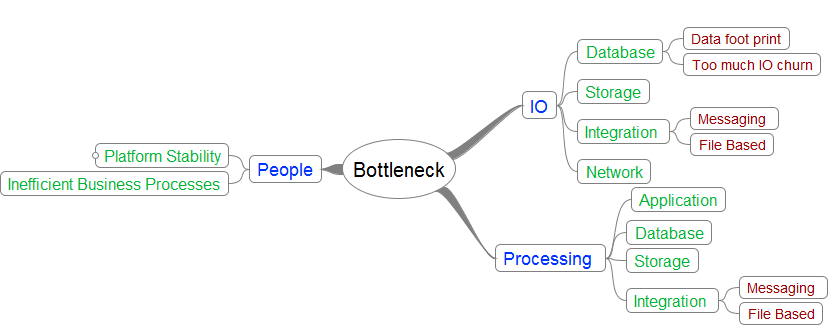
When tackling a complex platform, unless a methodical approach is adopted, fulfilling the front to back capacity becomes very difficult. In order to address the five principles discussed earlier, the first step is to assess and understand the different capacity impacting dimensions and their impact. Figure below shows three dimensions that need to be understood.

These dimensions can be further categorised as below based various dimensions like
Efficiency of processing, data storage , transmitting
What dimensions and levers drives the platform into constraints
What are the bottlenecks and what are those drivers ? what layer in the architecture - network, storage, business processing, UI, or a combination of all/ some hitting their peaks?
I have further dissected the above dimensions as below

.
A.1. Understanding the Architecture and its impact to Capacity
A poorly architected platform is the main reason for a platform to fail. Therefore, it’s important to understand the detailed application architecture first.For example, this system was primarily a pseudo event driven architecture with multiple logical components (1000+) that interact via messaging. Each component polls for work through database work tables and provide results to the subsequent processes by writing results to a work out table. This ‘heavy data movement’ architecture, which is likely based on older mainframe designs, creates significant stress on processing and IO - requiring additional infrastructure resources. The proliferation of hundreds of such processes continuously seeking for work aggravates this situation. This is compounded with significantly large, de-normalised data models that are used to pass data across these processes creating further strain on the database IO, messaging and storage.
A.2. Different facets of Capacity drivers
The meaning of capacity can have different facets that can depend on the type of data and the functions performed on that data.This becomes complex when common infrastructure is shared to perform different non-functional behaviours where the parameters that affects the performance is different from one component to another. Below diagram shows several examples.

A.3. Understanding the type of Bottlenecks
It’s a common misconception that adding more CPU will improve performance of a platform. CPU (or processing capacity) is only one of the key bottlenecks a platform can be impacted by. There are three types of bottlenecks that need to be understood and remediated.
CPU Bound
This is evident when the CPUs are almost fully utilized meaning there is not enough user CPU time available for processing the CPU instructions. This is applicable to any layer of the technology architecture spanning database, integration, and application components.
IO Bound
This is evident when there is significant IO wait times (not execution times) of CPU. IO bottlenecks can be either memory related IO, disk related IO and/or network IO that can be due to actual inter-process communication or persistence interaction with a remote storage and/or database.
People/Process Bound
Sometimes even though a technical improvement can be made, due to the way functionality is implemented or processes were defined, the way users utilize the platform may be inefficient, hindering any capacity improvement. For example, in this system it’s a fundamental design to proactively create exceptions until they are closed at end of day.
A holistic approach requires one to understand;
What types of bottlenecks exists
In which layer(s) of the architecture they exists
Differentiating the Observation vs. Root Cause
One common mistake is to jump to early conclusions in identification of the cause. What you see at the end breaching SLA may not be the cause
After taking all the above into consideration, a front to back view needs to be obtained.
Understanding the performance impacting dimensions is essential for one to answer these questions:
What is the capacity limit of each component?
What functionality is limited by this capacity?
When the capacity driver affects the platform? (trades, positions, intraday vs. daily trades etc)
Which layer is bottlenecked?
What is the reason for the bottleneck
… and finally
What can be the solution?
B.Creating Solutions
Up to now the process covered understanding the platform and its relation to different facets of capacity. Now let’s look at how different solutions were formulated. Irrespective of the solutions undertaken, they should address one or more of the five principles discussed above in the context.
The types of solutions can be driven by several factors, namely:
1) How soon the capacity remediation needs to be addressed?
2) How risky is the approach?
3) What effort/money we expect to spend on the solution?
4) What is the sustainability of the solution (i.e. improving efficiency vs. stop gap)
In this system a hybrid approach was adopted that constituted a Top Down (address by changing the architecture or design) as well as a Bottom Up analysis to provide a consolidated growth in capacity. The prioritisation of the solutions was then based on the factors considered below.

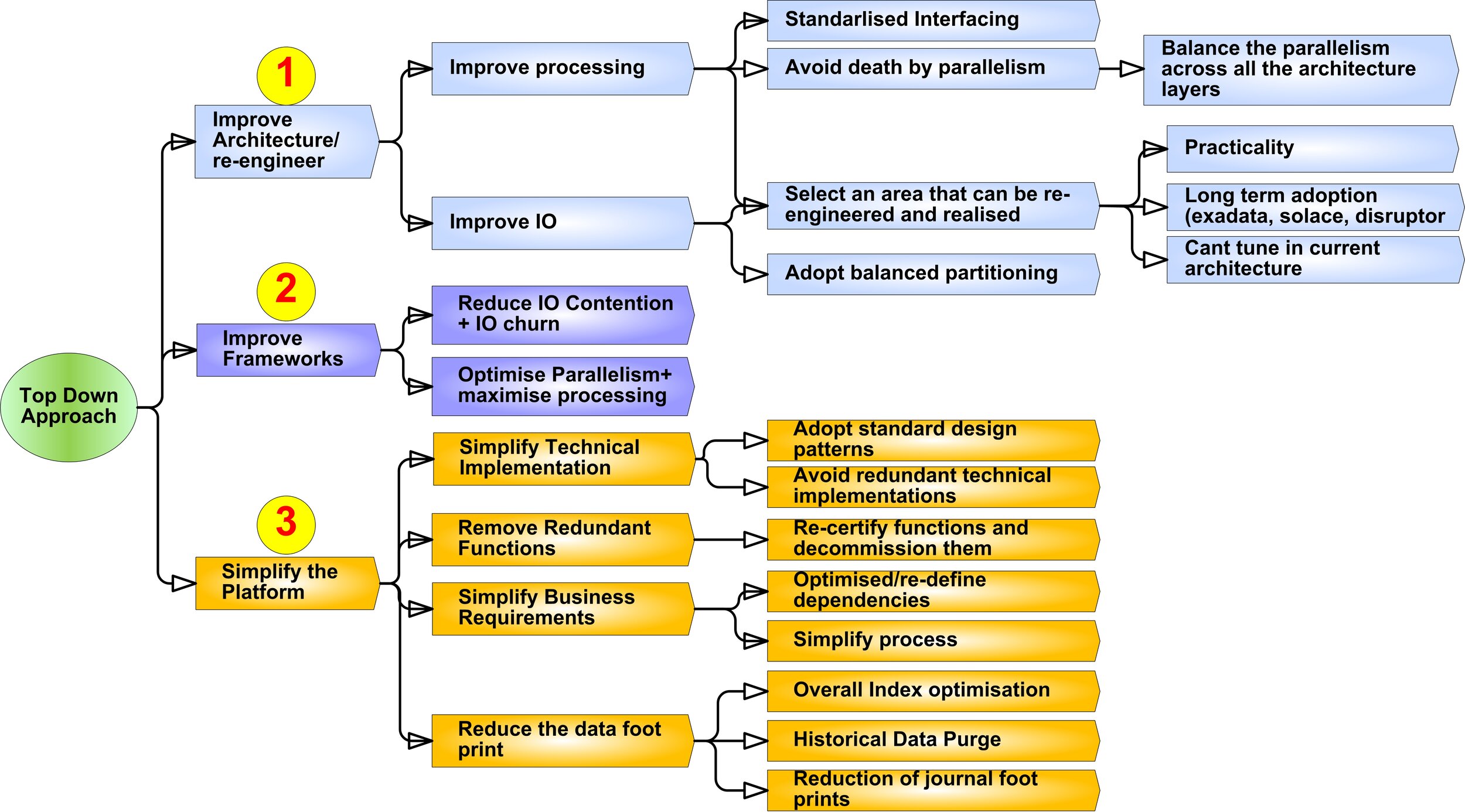
B.1. Top Down Approach
The top down approach is based on several key principles
Rather than focusing on just the immediate area, look at the front to back architecture to balance the capacity across the whole platform.
Instead of creating point solutions, formulate more over-arching solutions (architectural/framework) that will bring benefits across wider landscape. This can be ascertained by input gathered from the system architecture study.
Get a proactive view of relative capacity across the whole platform rather than on a particular component and balance solutions to achieve a balanced increased front to back.
Focus more on improving the efficiency rather than headroom addition.
There are several types of dimensions that can be looked at in top down approach as depicted in below pic;
B.1.1. Improve the Architecture
Changing the fundamentals gives wider and long lasting improvements but it can be costly and time consuming. When tackling a complex platform it is essential to ensure continuous improvements flow through the platform and the improvements are realized across the regions.
In this system, one of the key areas that required a capacity uplift as well as stability/simplicity was on the front office trade capture functionality. The fragmented setup contributed to poor performance. It’s essential to understand that capacity is not just about ‘fast processing’ but must also avoid failures, improve straight through processing and ability to recover quickly. Achieving this through a re-engineering approach can be more effective than fixing an old platform.
Architecture simplifications include;
The key solutions implemented included:
Enforcing a single standard message format wrapped up in a API to replace N different formats in-situ across front office applications
Reduced the number of integration hops, and additional processing (for transformation, split, route)
At source validation done by API, assures capacity by improving STP.
Deploying High performance (>10x), resilient and highly available messaging setup running on appliance based middleware
Reduced the additional hops and processing required for fanning out the messages to compensate deficiency in messaging product
Automating recovery and graceful exception handling
Assuring system capacity by avoiding manual intervention and down time.
Death by Parallelisation
It’s a common practice, and was quite evident in the system, the proliferation of parallelism adopted across all layers of the architecture. For example parallelising application workers/threads, utilising parallelisation features in Oracle, parallelisation of messaging interactions (e.g. splitter, router).
Several principles need to be adhered to when seeking opportunities to achieve parallelism.
If the parallelisation is blocked by a shared singleton, the parallelisation will drastically reduce inline with the law or diminishing returns. This singleton can be small as a synchronisation lock in a hash map or large as a single instance process in a product (e.g. Oracle singleton Log Writer Process).
The throughput and capacity should be balanced across all architecture layers. i.e. there is less value in adding more application threads if the combined throughput of that cannot be met by the underlying database configuration.
Hence, parallelism can be exploited until all the layers in the architecture are optimised to utilize their IO and CPU resources (and not to jeopardise another layer).
The degree of parallelism in the system was unbalanced. Therefore, additional care was taken when understanding possible capacity improvements by enhancing parallelism.
Employ appropriate partition strategy
When IO and CPU resources are shared across different flows, there is always a tendency for one flow to overwhelm the others. Therefore when such shared resources exist, one must ensure:
Appropriate logical or physical resource partitioning is done based on the throughput expected of each flow
If needed increase the parallelism within each flow.
The following scenario explains such a situation in one of the legacy components in the system
Observation
The throughput of posting trades seem to go down when corresponding settlement events starts coming in.
Cause
The technical flows for both trades and settlement paths were analysed, including measuring the throughput at each step and the bottleneck came down to a set of shared business engines that performs the journal updates.
Solution
Partition and scale out the number of engines allocated specifically for trades posting and settlement posting so that
Engines are not shared across two flows
Each flow has sufficient throughput to handle peak volumes.
Why?
The technical components upstream to these business engines had much higher throughput to scale out and hence the increased parallelism didn’t impact any other resource contention. Also the downstream component, database has more parallelism than the combined flow interactions could handle. Hence the front to back parallelism was not compromised.
B.1. 2. Improve Frameworks
The understanding obtained from the architecture study will help addressing over-arching improvements. In this case, CPU and IO overhead was significant due to the way data was transmitted across granular processes (i.e. polling, work-in/work-out tables). Adding headroom to CPU and improving the UI stack only provide a limited (and costly) head room. However, improving the efficiencies of these processes is more sustainable and following scenario explains such a situation.
Observation
Low throughput in cross component communication visible through the significant backlog building in message channels
Cause
Significant IO waits due to the large number of commits/churn into databases and journals (state files)
Solution
Introduce batch commits to C++ and java work management components. Same time ensure the platform can handle idempotent processing.
Why?
Reduce the # of commits reduces the rate IO was generated while that in-turn reduced the overhead on file system, database and even messaging platforms. The resultant improvements provided performance beyond 10X.
B.1. 3. Simplify Processes and Platform
Very simple and quick benefits can be achieved by just removing unnecessary processing. This can be done by
Simplify Technical Implementation
The best solutions are in general the simplest solutions. A technology should be understood based on several factors
The key patterns its best suited for
What anti-patterns should be avoided and when it should not be used
And what are its pros and cons
Below are some scenarios.
Observation #1
The SLA for sending a report was breached
Cause
The receiving components received the files late due to the significant time spent in the file transmission, compounded by sending the same unzipped file twice to the same server!
Solution
Send only one file zipped ( so naive!)
Why?
Sending two large unzipped files is much more time consuming that sending one zipped even after adding the zip and unzip times!
Observation #2
Publication of balances from the reporting platform to downstream consumers is breaching SLAs.
Cause
Unwanted steps in processing including
Publishing a pre-generated c.800G file into messaging
Consuming the file, and loading into a staging table
The same source file is generated and consumed by another process!
Solution
Avoid the publication of large file to message infrastructure
Simply populate staging table from the corresponding source transaction tables
Why?
Spent effort in transferring a single file when the source and target are in the same platform sub-domain!
Remove Redundant Functions (re-certify) and dependencies
As a platform ages and housekeeping is not maintained, there can be much unwanted functionality lying around in the platform that eats up scare platform resources. In this system, when contentious functionality was found, one of the simple things done was to evaluate the need for that functionality and where no longer required to simply de-commission it. Such analysis paved the way to decommission high resource consuming reporting jobs. Another flavour of this can be re-defining the dependencies among the different functionality. For example, remove unwanted parent-child dependency between two schedules (e.g. control M) when there is no data, integration or functional dependency between them. Capacity headroom was achieved in in certain batch process with 100 jobs, by removing a dependency of a parent job that didn’t have any data, integration or business logic related dependency, and hence enabling to start the batch much sooner. Creation of a DAG ( Directed Acyclic graph) of dependencies helped in forming the right sequence and parallelisation
Simplify Business Requirement
Contention can be introduced by wrong implementation or interpretation of functionality. Following scenario explains such a situation.
Observation
Providing matching breaks to the Operations is delayed due to the slowness in exceptions processing.
Cause
Exceptions/tasks were proactively generated even before the street side of the trade has not arrived or not expected to be arrived. And when the street side arrives and matches more than 99% of these pre-created exceptions had to be rolled back. This created redundant processing as well as created a significant backlog to roll back
Solution
Stop generating pre-planned exceptions, but rather generate exceptions when either matching of both sides are completed or a particular SLA is breached for a particular exchange.
Why?
Redundant exceptions generation and subsequent rolling back slowed down the overall process as well as hindered actual exceptions been reported on time to the operations.
B.2. Bottom up Approach
Several approaches can be adopted here as well. But in principle, this is about providing additional head room by means of either providing processing capacity or IO capacity by focusing on specific bottlenecks.
The Improvements can be/should be looked at in each of the architecture layers of the platform spanning application, database, storage and integration.
The below sections articulate these by breaking down to different layers of the architecture, and each approach is analysed in relation to the 1) observation 2) cause and 3) solution.
Below diagram outlines some of the dimensions I considered.

B.2.1. Application Layer
In this platform as almost all the business logic was implemented in database, the thin application layer was mostly responsible for reading data out from database or writing into the database. There were several areas where the overhead of even this simple process was too significant.
Observation
The time spent in between reading from the data for and publishing out a single message was too high.
Cause
The framework design stipulated expensive/poorly written message transformation logic that took more than 80% of the roundtrip time.
These transformations didn’t add any value to either downstream or upstream processes. This was aggravated by expensive XML marshalling/un-marshalling introduced during the height of XML adoption
Solution
Direct read and 1:1: publishing in simple delimited format removed this transformation overhead.
Further read IO improved by increasing the data buffering in the application’s oracle driver (i.e. pre-fetch)
Why?
Simpler to change, test and deploy
Improved the through by 4X
B.2.2. Database Layer
There can be many options to address database layer bottlenecks. In addition quick infrastructure upgrades we carried out some key solutions ( that actually comprised of 100 tasks)
Three such examples are explained below, covering different dimensions.
Observation #1
Significant CPU and IO overhead in Key Databases from specific PL/SQL code
Cause
Poorly designed /written SQL procedures utilising too much CPU and IO
Solution
Select the worst performing SQL w.r.t. IO and CPU utilisation and improve these without affecting the functionality. Patterns adopted included reducing physical IO, improving execution paths (indexes), effective and controlled usage of query parallelism.
Why?
Rather than giving further headroom, reducing the IO and CPU churn is longer lasting and hardware sympathetic.
Observation #2
Exposing the IO bottlenecks after CPU upgrade!
Cause
Solving CPU bottleneck, opened up the next level of bottleneck in IO, mainly due to the high volume of consistent IO writes happening. Some due to the fundamental architecture of the platform
Solution
Improve the IO stack by Oracle Direct IO configuration for the Log Writer
Why?
Singleton Log writer performance was the immediate bottleneck in the IO stack. This paved way for further work planned for tuning the IO interactions across the OS IO Stack
Observation #3
Intra-day holding journal data from transactions table appearing in the reporting database was significantly delayed (e.g. 3-4 hrs), impacting the operations getting up-to-date view resulting in operational, reputational and regulatory risks.
Cause
Replication from the positions and balances OLTP database to the reporting platform was hindered due to the inefficient configuration of the replication tool , Golden Gate
Solution
Improve the throughput by having parallel replication thread from source to target database
Why?
No comparable deficiencies in the redo log generation at source or the application of the changes in the target
B.2.3.Messaging Layer
As the platform has 1000+ messaging points hosted on 30+ messaging servers instances (i.e. Channel Servers), there was significant contention in the integration Layer. Following are some scenarios and solutions.
Observation #1
Significant throttling in processing trades to generate confirmations.
Cause
Even though the up stream process submits trades at a much higher rate, confirmation manager was unable to consume them at the same rate due to the significant IO contention in messaging servers.
Solution
Simplifying the integration flow by removing additional messaging integration steps and thus reducing the IO contentions
Why?
Additional steps put more IO contention (read/write/log) for the same effective business events. Removing the unwanted steps reduces the additional IO.
Balancing the workload across flows
Even though not specific to messaging, it’s essential that the platform’s ability to handle load is balanced out across all business flows. The below scenario explains one example.
Observation
One of the front office integration flows exhibited a lower throughout compared to another similarly loaded flow.
The integration set up was identical.
Cause
The flow with the lower throughput had messaging servers (in this case channel servers) over-loaded due to they been used at different steps in the integration flow, putting significant back pressure on them.
Solution
Re-balance the channels under load so that a dedicated channel server was allocated to each of the steps avoiding one been used across different processes.
Why?
Each server instance has an optimum thread and journal configuration set up. Excessive number of transactions put more IO contention and context switching on each channel server instance
B.2.4. Improving Stability
Capacity is not only constrained by how much work can be done at which speed, but also its ability to be resilient and available while processing high volumes. Improving the capacity can improve the stability of the platform and also conversely improving stability can improve the capacity. Below is one example.
Observation
SLA Breach in critical batch job
Cause
Daily manual intervention up to 5 hrs to fix the issues in the suite of control M jobs, due to the wrong implementation of the functionality!
Solution
Obvious solution of incorporating the correct functionality to the sub-steps that were failing.
Why?
This not only wasted production support personal time as well as impacted a key SLA!
B.2.5. Interplay between IO and Processing bottlenecks
There can be situations where the observation can point towards a processing capacity limitation, where as this can be due to an IO contention and vice versa as well.
Observation
The System CPU utilisation of the server running messaging infrastructure was significantly high
Cause
Multiple instance of messaging servers continuously invoking system calls, especially IO traps to get a handler to journal the messages. This was due to the write-head log size was small, resulting in the continuous need to request system IO calls to write to disk.
Solution
Avoid the IO contention by increasing the write-ahead log size to reduce the frequency of IO Calls, ensuring the memory requirement (to cache the logs) didn’t compromise the available resources.
Why?
The IO contention resulted in a visible CPU contention. Adding more CPU would have not solved the problem long term.
Step C: Ranking and Prioritisation
Up to now the process addressed two aspects:
Understand the platform and its relative and absolute bottlenecks
Understand the architectural (over-arching) and point solutions to remediate them
The next step is ranking them based on several criteria:
Which solutions give the highest up tick
What solutions are comparatively simpler? i.e. less invasive like simple hardware uplift.
The risk of the change. This can be based on the
# of business flows/processes impacted
Significance in deployment
Significance in testing.
How well the benefit balances out with the front to back improvements. For example, the capacity increase in a particular release should be balanced (as much as possible) across all functions without skewed to a few.
Based on the priority, a book of work (BoW) can be created and a set of solutions can then be allocated to each release in the year.
Step D: Deliver Solutions
Based on the ranking, the prioritized items were added to the year’s BoW for delivery and planning. The Solution Formulation section discussed some of the areas but the actual solutions are specific to the underlying platform and its architecture. The dimensions addressed in the Solution formulation section can be used as templates and areas for consideration.
Step E: Measure, Model and Re-baseline
After delivering the solutions it’s essential that:
The improvements are measured
Models are updated to reflect the changes
Re-baseline the capacity parameter to reflect the improvements and/or identification of new bottlenecks.
New type of bottleneck surfaced in the same point/layer of the architecture.
For example, when CPU bottlenecks were addressed in Trades database subsequent IO bottlenecks were unearthed.
New bottlenecks in different layer of the architecture have surfaced.
For example, when the bottlenecks in the databases were addressed, further bottlenecks were unearthed in the messaging/integration layer.
New bottlenecks in different function/location/points have surfaced.
For example, when Trades processing improvements were done, bottlenecks in further downstream processes like confirmations generation surfaced.
Hint #1: It’s very important to have an early view of the next level of bottlenecks. This can be achieved by observing the architecture properties and understanding anti-patterns that would obviously limit capacity or by measuring the next level of perceived bottlenecks, for example extrapolating the possible thread utilisation or rate of IO, Storage growth.
Hint #2: Another way to test the next level of bottlenecks is component wise stress testing. This is useful when the predecessor components have a lower throughput compared to the downstream components and hence until predecessor component is remediated, the actual throughput cannot be injected downstream. By short circuiting the flow and testing the downstream component directly can unearth next level of bottlenecks in the flow.
Hint #3: Ensure the relative capacity limits of the platform in understood front to back.
In the front to back, top down approach adopted within the system the third hint above was addressed proactively by means of identifying the bottleneck and capacity of each point up front.
Subsequent iterations
Solving capacity of a platform cannot be realised by a single cycle. Each release can represent a single cycle and the results from this release and achievements confirmed, need to used to re-baseline the limitations and hence the solutions.
Subsequent release will repeat the process;
Formulating or ratifying the solutions based on the results
Priorities solutions
Deliver solutions
And again measure the results for subsequent release.
Lessons Learned
The capacity improvements were delivered in conjunction with other deliverables. Some of the key lessons learned during past year are.
1) Start from simplest solutions
It’s easier to uplift the infrastructure (increase the number of CPU/cores, migrate to a higher end server. This will not make the application run more efficiently but give more headroom in the interim until subsequent releases can bring in more efficiency through application improvements.
2) Do not try to do everything in a single release
Even though there can be enough arguments to do most of the things in a single release (i.e. less overall testing effort) when remediating acomplex platform it’s more effective to deliver in shorter cycles. This will not only build confidence but also
1) Provide more insight to further issues that were not identified
2) Tune and improve solutions
3) Improve the way capacity is tested and monitored.
1) Be ready for surprises
When working on a complex platform there is no lack of surprises. The lack of standardized design patterns and implementation patterns and more importantly poor development /design patterns surprised the team in various instances. The intricate tentacles of business logic proliferation impacted some of the capacity solutions and also significantly expanded the testing scope. This becomes more relevant when moving from less-invasive infrastructure changes to framework and functionality impacting changes. Hence, investing more time on up front due diligence and impact assessment is imperative.
2) Have a representative stable performance testing environment
The testing environments were not representative of the production environments as a result of poor maintenance of these environments. There were differences in infrastructure setup, a lack of monitoring and housekeeping, capacity related constraints, and incorrect configurations. This not only impacted getting comparative results but more importantly impacted the stability and in turn delayed our testing.
3) Automate realistic front to back test cases
When environment time is limited, aggravated by lengthy testing schedule, running comprehensive tests was virtually impossible. To achieve the best realistic results in a limited time, The testing team moved away from unrealistic and isolated tests to testing actual business flows using representative production loading patterns. This helped us move away from extrapolating capacity based on available capacity to benchmark limits based on real performance testing.
4) Ensure proper monitoring in place
Again the lack of production equivalent monitoring in testing environments at all the requirement points in the architecture made capacity realisation unrealistic. Hence, ensuring the required points within the flows are monitored is essential. In some cases, real time monitoring and capturing of the run time behavior gave significant insight on the dynamic shifts of IO bottlenecks between components and layers in the architecture.
Hope you enjoyed reading this blog.. I had only managed to provide few of the 100+ solutions we delivered. But tried to give a concise view while covering the overall approach and fundamental thinking. Any one needing a more detailed technical and architectural discussion can DM me